Securing the Stack: Starseer’s Latest on Vulnerability Scans, Model Patching, and Graph Insight

Starseer Update
We have been very quiet the past few weeks, so its time for another update! I remember when Tim and I started the company, we were talking about how regular updates would be critical for us, we went back and forth on weekly updates, every other week, was that not enough? Turns out the more realistic answer was monthly! Unsurprisingly, we underestimated how many other things are going on when you are starting something from scratch.
What have we been doing? It can be categorized into talking, coding, and selling.
Talking - Over the last few weeks we have talked to a LOT of people. We have talked to friends, founders, venture capitalists, CISOs, technical teams, and many more. It has been an absolute whirlwind of discussions, feedback, education, sales, and further introductions. One of the truly amazing discoveries throughout this adventure is that no two meetings are alike! We can bring the same material, and every conversations brings about discussions of new applications, extensions, and approaches - it is incredible. Throughout this process we have been fortunate enough to meet a few key people who have been extraordinarily helpful in various ways - from endless introductions, to strong technical and market insight. We have immense appreciation for these folks and Starseer is better for it.
Coding - While it seems like entire days are taken up by meetings, we still find some time to build out new features. Sometimes I think it is the coding that keeps me sane(ish). Being responsible for many of the changes in the code base involves staring at the product every day and it is easy to think that the product hasn’t changed that much since we last showed it off publicly. As I glanced through features I wanted to touch on for this blog post, it was a lot more than expected. There is one big feature I want to discuss in significant depth: Model Vulnerability Scanning & Management, a very large new feature we have developed. Prior development efforts I’ll highlight is our easy to use Model Patching system, as well as Model Graph Diffing for all of your model analysis and modification needs!
Selling - If you have ever worked in a larger company, you know how long and complex this process can be, and how many stakeholders need to be on board to get the process completed. We have had an incredible amount of interest and every demo we give results in excellent feedback and some comments along the lines of “I didn’t even know this was possible”. Not only is it possible, it’s just a few clicks away for anyone! Credit to Tim here as he wrangles most of this process so I can continue to churn out features, but it feels good to hear such positive feedback from customers about the product as whole.
I think that wraps it up for the general company update! As always there are so many things in the pipeline that I want to talk about, but I think this is plenty for today. Onward to the new tech!
Technology Spotlight
When I told Tim I was writing this blog, it was initially about our new model scanning functionality, but as I wrote it grew in scope to include a few other highlights that we haven’t talked about publicly. I first want to highlight some of our previous developments before diving into model scanning so without further ado, let’s talk about model patching.
Model Patching
My vulnerability research background means reverse engineering is always on my mind. Diving into model security, model computation graphs are exceptionally interesting to me. Even before we started Starseer, one of the most interesting pieces of research I read was on ShadowLogic from Hidden Layer. The core finding isn’t necessarily shocking - “You can modify code to alter behavior”, but the blog is excellent and the impact is an important point to make as many people just accept the risk of “black box” neural networks without understanding what that entails. One takeaway I had was, “How would we detect this?” and down the rabbit hole I went. There are two primary aspects of this question:
- How do I easily backdoor models for testing?
- How do I detect backdoored models?
Being able to backdoor models is a bit of a “nerd snipe” if you will. The ShadowLogic blog post is cool, and I want to be able to reproduce that. After some time diving through graph formats, I implemented a reliable way to add single nodes within our platform itself. Over a week or so I expanded that capability to arbitrary subgraph injection which you can see below is a single click. Given a few constraints (Matching number/type of inputs and outputs) now anyone can reproduce the ShadowLogic blog with their own subgraph and a few mouse clicks. While ShadowLogic is focused on using this subgraph injection as a malicious example, this type of model modification can be used to add beneficial additions as well, such as linear probes, and sparse auto-encoders to help with interpretability of a model. We believe that making this an accessible process is an important educational tool for helping individuals and organizations understand what is possible with models for both attackers and defenders!
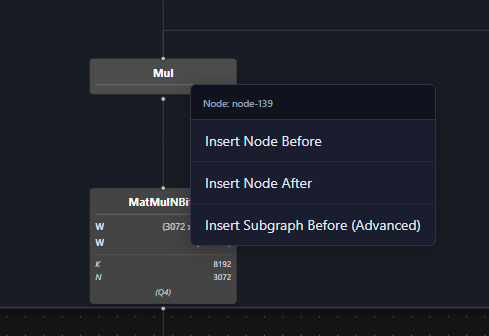
Now that we have built out a way to reliably reproduce the ShadowLogic backdoor, let’s switch gears to talk about how we would detect this type of backdoor since we are here to solve problems, not create more! Previously we showed off our graph view and we figured, what is better than one graph view? Two graph views obviously!
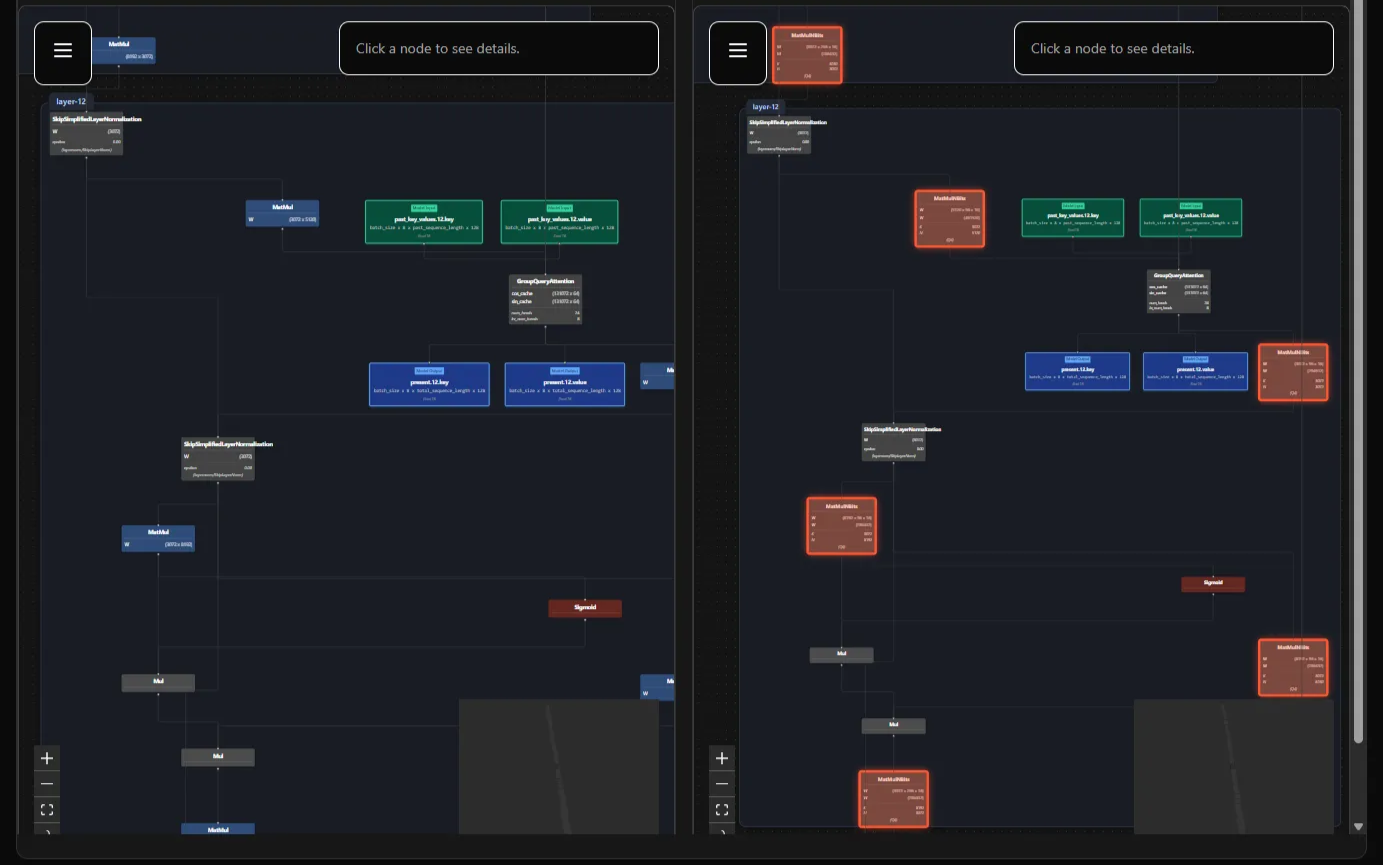
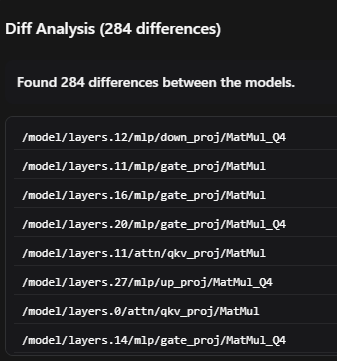
We implemented a diff tool for quickly identifying changes between two model graphs. This allows us to not only take note of any additional nodes, but also can let us check two models that are seemingly very similar. The eagle-eyed reader here may notice that both of the models above are Llama 3.2, but there are a bunch of highlights - that isn’t a bug. The version on the right is a quantized model, which drastically changes the computation graph - since quantization reduces the size of model weights, the computation graph must change to support their new size. We can not only identify backdoors, but we can also identify any changes to the model as a whole - malicious or not! Now those of you reading and thinking, “Wow that is cool, (It is.) but I don’t want to use a UI, that is clunky” well the good news for you is the entire platform is backed by an OpenAPI defined API. If you want to diff models without the UI, you can! The API still returns back all the changes similar to what is seen in the screenshot below with optional additional telemetry for deeper analysis.
Practical Applications for Graph Modification
Second, I want to talk about the capability that is really developed here. We have developed the first (to my knowledge) ZeroPatch equivalent for neural networks. This unlocks a plethora of really important capabilities for us and our customers. When we combine patching with our concept mapping capability (a future blog post), graph analysis tooling, and our soon to be discussed vulnerability scanning and management, we have some very exciting applications. This patching has so many use cases - optimizing compute resources by modifying the models in place, true model introspection at runtime, and inference-time vulnerability patching just to name a few!
At this point there are two primary statements that need to be addressed:
- “Diffing is great if you have something to diff against”
- “What vulnerabilities would you even patch”
These are valid points and this is a great segue into the feature I set out to talk about Model Vulnerability Scanning & Management.
Model Vulnerability Scanning & Management
I briefly want to take a step back from the technical spotlight to give a little background on this feature as I think it is helpful.
Background
We have had many discussions with people over the past few months, however one of the most impactful individuals I alluded to earlier was one of the real drivers for this feature set as they were able to clearly articulate the reasoning behind some of their platform suggestions. Throughout our conversations they were impressed by the capability of the platform, but asked about model procurement and supply chain, trust requirements, and how can we leverage our platform to provide near term impact for where people and organizations are today. I think we as a company are better for those conversations, and it really opened up a whole new story for the Starseer platform as a whole. We continue to utilize interpretability for security, but we also help customers mature from where they are today, by accelerating their path to success. This new functionality extends the platform’s reach to include more of a model’s lifecycle as a whole and helps build a strong security foundation for models that are being brought into an organization. We want features like model diffing to be useful for Digital Forensics and Incident Response, and we need to have a trusted copy to diff against which comes from model procurement. Similarly, if we determine we need to patch a model, some of those patches have to occur before it is ever run.
What is the problem?
Organizations want to adopt AI models where it makes sense in their business which we can break down into API usage through a provider like OpenAI, or self-hosted usage. We are focused on self-hosted models with these products - open weight models, or internally developed models. In both of these cases we have a challenge to overcome, how trusted is the model as it enters production?
For open weight models, there are a few places online to acquire them , but I think it’s fair to say that today the most common is HuggingFace. HuggingFace is a massive repository of open weight models that are for an infinite number of applications that can be uploaded by anyone. You can download an LLM from a known model provider such as Meta, or a trading model from TrustMeIWillMakeYouRich, and the process isn’t much different between them. While models may feel less like executables, they are arbitrary code that can be executed on your computer. The potential benefit of business acceleration means they are being deployed regardless.
For internally developed models, how do you determine that the model hasn’t been tampered with prior to deployment? Has the model been quantized (made smaller) without a formal process change? Did an engineer push the wrong version to production? Was there a supply chain issue for a piece of the model? General software has many solutions for this type of CI/CD investigation, but models don’t currently have the same software available.
Now this is not an entirely new concept we are talking about here - ProtectAI released tools like modelscan and JFrog has some model scanning functionality built in, but the more we have explored the space, the more we believe that our approach is differentiated by providing deeper inspection into current and future attacks.
Our Solution
What is our solution? Well here is an example for the ScanMe/Models HuggingFace repository.
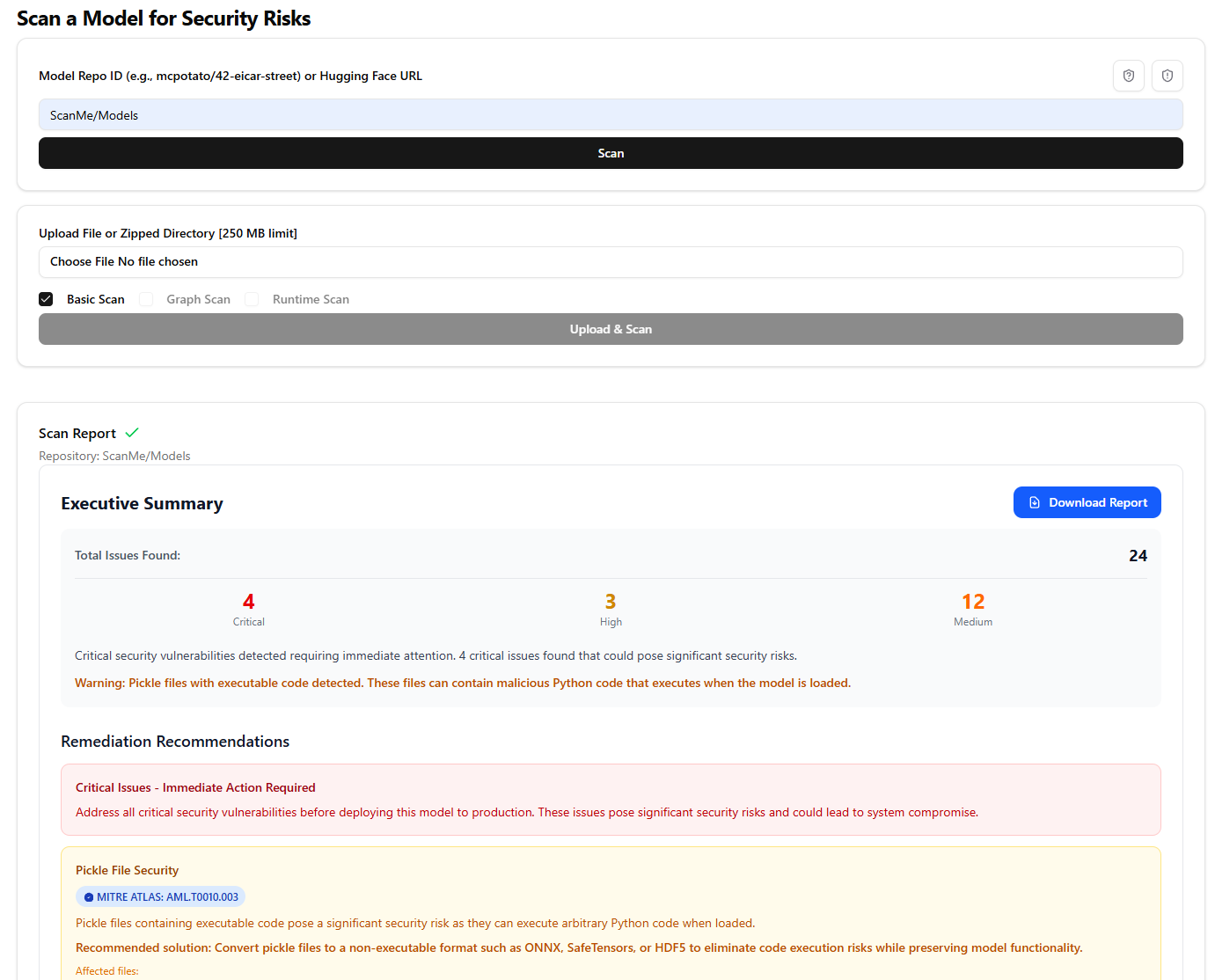
This repository is meant as a sample for scanning various dangerous types of files, and you look for yourself that even at this basic level, our scanner already shows parity with other HuggingFace model scanning tools. Parity isn’t a better approach though, so let’s dive in.
We only need the computation graph for the initial scanning functionality (foreshadowing!) so the files are relatively small and scanning is extremely fast. Whether you put in a Hugging Face repository, or upload a model file from your local device, the functionality is the same, with an API available!
Scans produce downloadable Markdown reports, and an example for the ScanMe/resnet-backdoored repository is attached to this post as an appendix.
If you want MITRE ATLAS mappings - We have you covered, we have built out support for the mappings on our reporting and will continue to expand and improve it over time.
If we move past the executive summary with some other useful information we see the results at a glance.
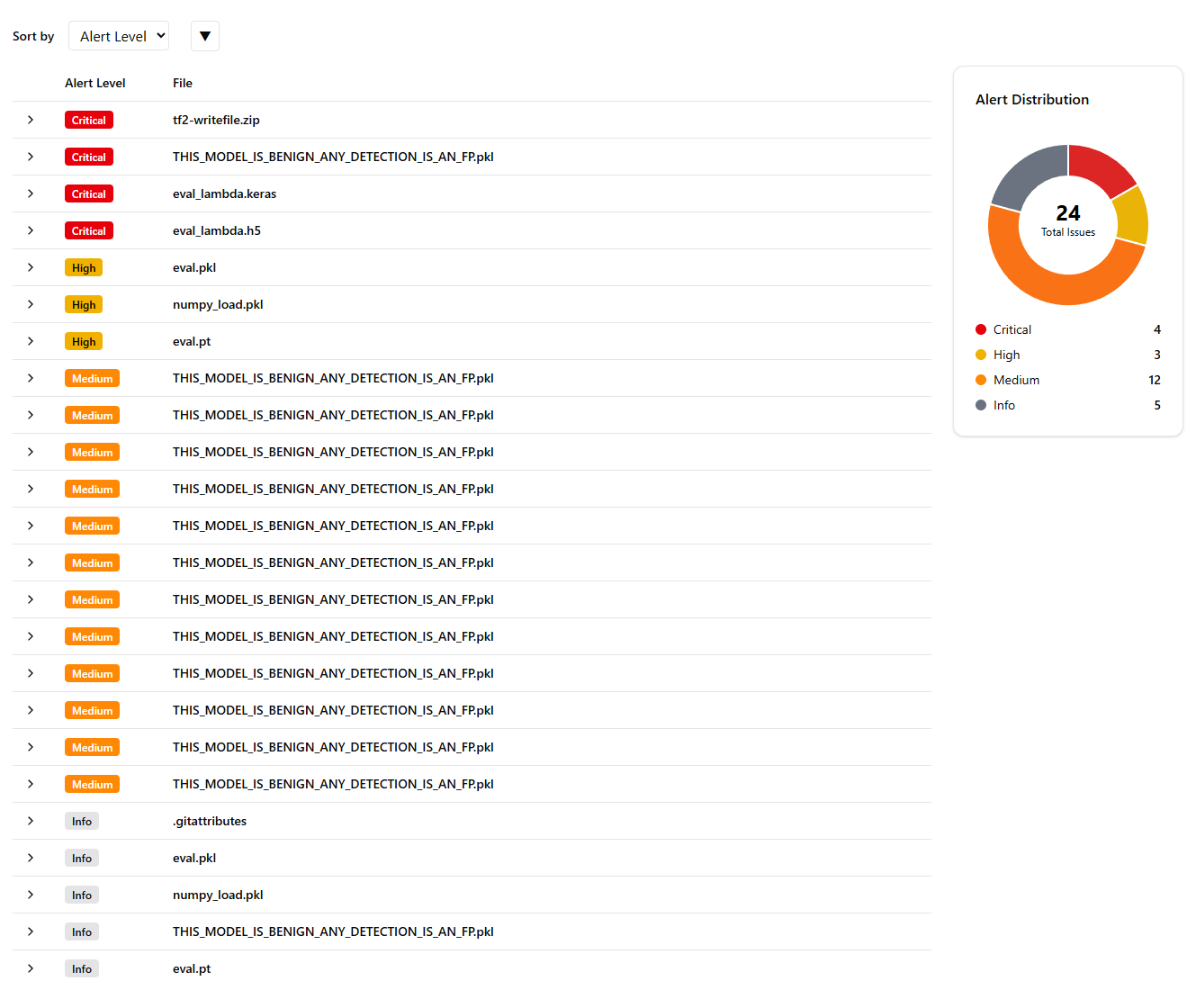
We can see all types of alerts here from the models in the repository. The first part of our approach is surfacing information that explains why a file is potentially dangerous. A great example of this is the eval_lambda.keras model.
Lambda layer found within model configuration that contains dangerous functions such as eval or exec.
Lambda layers can be used to execute arbitrary code. The recovered code object is :
Code { argcount: 1, posonlyargcount: 0, kwonlyargcount: 0, nlocals: 1, stacksize: 2, flags: OPTIMIZED | NEWLOCALS | NOFREE, code: [116, 0, 100, 1, 131, 1, 112, 5, 124, 0, 83, 0], consts: [None, "\nprint(\"This statement was printed by a Lambda layer that calls Python's eval() function\")\n"], names: ["eval"], varnames: ["x"], freevars: [], cellvars: [], filename: "/Users/rtracey/Desktop/Testing/scripts/generate_h5.py", name: "<lambda>", firstlineno: 4, lnotab: [8, 0, 4, 2] }
The attached file is base64 encoded, and then marshalled, but once unmarshalled can be disassembled using Python’s dis module.
4wEAAAAAAAAAAAAAAAEAAAACAAAAQwAAAHMMAAAAdABkAYMBcAV8AFMAKQJO+lsKcHJpbnQoIlRoaXMgc3RhdGVtZW50IHdhcyBwcmludGVkIGJ5IGEgTGFtYmRhIGxheWVyIHRoYXQgY2FsbHMgUHl0aG9uJ3MgZXZhbCgpIGZ1bmN0aW9uIikKKQHaBGV2YWwpAdoBeKkAcgQAAAD6NS9Vc2Vycy9ydHJhY2V5L0Rlc2t0b3AvVGVzdGluZy9zY3JpcHRzL2dlbmVyYXRlX2g1LnB52gg8bGFtYmRhPgQAAABzBAAAAAgABAI=Breaking down the alert: we have a brief description of why this is an alert and information we can recover directly while scanning. This information provides important context for deeper analysis such as constants in the Lambda layer, and even gives us the base64 encoded Marshalled python data. This is an area where integration with additional analysis tools can further enrich alerts and will likely be expanded in the future.
Something we have to talk about though is false positives and why this is a hard problem. Luckily that is tackled by this file THIS_MODEL_IS_BENIGN_ANY_DETECTION_IS_AN_FP.pkg, why do we have so many alerts? Well I picked this example to talk about it directly and all of these alerts boil down to the same issue. This model has a ton of imports in the pickle file. It is generally considered unsafe to have imports in these pickles because the code is executed upon deserialization. Here is a list of all the imports (This is reported in the info alerts above, they all vary slightly, but useful information that isn’t security critical)
{
"remaining_bytes": 0,
"total_pickle_ops": 72637,
"imports": {
"ultralytics.nn.modules.block": [
"C3k2",
"Bottleneck",
"C3k",
"SPPF",
"C2PSA",
"PSABlock",
"Attention",
"DFL",
"Proto"
],
"ultralytics.nn.modules.conv": [
"Conv",
"Concat",
"DWConv"
],
"torch.nn.modules.conv": [
"Conv2d",
"ConvTranspose2d"
],
"ultralytics.nn.tasks": [
"SegmentationModel"
],
"collections": [
"OrderedDict"
],
"__builtin__": [
"set",
"getattr"
],
"torch.nn.modules.linear": [
"Identity"
],
"torch": [
"HalfStorage",
"LongStorage",
"Size",
"FloatStorage"
],
"torch.nn.modules.pooling": [
"MaxPool2d"
],
"ultralytics.nn.modules.head": [
"Segment",
"Detect"
],
"torch.nn.modules.batchnorm": [
"BatchNorm2d"
],
"torch._utils": [
"_rebuild_parameter",
"_rebuild_tensor_v2"
],
"torch.nn.modules.upsampling": [
"Upsample"
],
"torch.nn.modules.activation": [
"SiLU"
],
"torch.nn.modules.container": [
"Sequential",
"ModuleList"
]
},
"extension_registry": {}
}Diving into the import list and associated detections - the Critical alert is based on getattr as this is a dangerous python function to have in pickle files as it can result in arbitrary module calls such as system or eval that execute arbitrary code. Without a full pickle disassembly and analysis it is difficult to determine if getattr is safe or unsafe. Moving to the other Medium alerts, each of these represents a single imported Module and all of its imported functions. It is not an easily maintainable approach to build a “Block List” or “Allow list” for every python module in existence, the scope entirely explodes! Instead we have landed in a middle ground, with known dangerous functions like eval or system marked Critical while unknown modules are marked as Medium alerts. We maintain and update a list of known safe modules that are fairly common in these model formats. An example of one such is the torch.FloatStorage as it appears in almost every model file due to needing to store tensors that are often Floats. This example model is built in a unique way for the sake of testing detections (which is good), but also uncommon, and as such we believe we should surface potential issues rather then assuming they are safe. When we look at this list as a whole, it’s reasonable to say that it looks fairly benign, and the length of time to check the imports is insignificant compared to the damage a dangerous import can cause when loaded. From our experience each organization has a different resource load and risk tolerance around these, which is reflected in how we support both high level overviews as well as the information for deep dives.
Why the Starseer approach?
I believe that our approach for scanning dives significantly deeper into the model formats themselves, this is not flagging a pickle file because it ends in .pkl . Our approach is a deep analysis that will improve over time as vulnerabilities continue to be discovered in models and model formats. This is only the first step of our model scanning pipeline! When I talked about model diffing earlier, we needed a trusted model to diff against, so how do we tell if we are downloading a backdoored model? This is where our approach shines, due to our work on the Observatory platform, we can leverage our multistage scanning process for fast, easy to understand insights on models. By leveraging the computation graph of scanned models we can do backdoor detection for a model without a “known good” version to provide even more protection before a model is brought into the organization at all.
As we look to what this scanning functionality will look like in the future, we believe it strongly mirrors what the Cybersecurity market has already adopted for securing an enterprise. Static Scanning of data at rest, detailed assessment of computation before execution, and sandboxed execution for holistic insights. Our Observatory platform perfectly powers this fully encompassing solution and that is our advantage!
How does this fit?
So is Starseer just going to scan models now? Absolutely not. I believe that this addition makes an even more compelling story for approachable and secure neural networks. Not all organizations will be at the point that they need the deep insights that our platform provides. Part of the organizational maturity needed to progress toward leveraging those deeper insights is to build a baseline of trust for previously untrusted models. By helping organizations ingest untrusted models, we are meeting more organizations where they are today, while preparing them with tooling they need to accelerate their AI security posture!
When we started this feature set, we already liked the idea and the value it added to our platform, but in addition to the conversations we had, the recently revised Executive Order 14144 called this approach out specifically. One of the very relevant excerpts:
“(b) By November 1, 2025, the Secretary of Defense, the Secretary of Homeland Security, and the Director of National Intelligence, in coordination with appropriate officials within the Executive Office of the President, to include officials within the Office of Science and Technology Policy, the Office of the National Cyber Director, and the Director of OMB, shall incorporate management of AI software vulnerabilities and compromises into their respective agencies’ existing processes and interagency coordination mechanisms for vulnerability management, including through incident tracking, response, and reporting, and by sharing indicators of compromise for AI systems.”;
Which is even more validation that this was a strong addition to the Starseer platform for the future!
Conclusion
There are so many cool features that I want to highlight, but I think that is a good place to stop for today. It excites me that every conversation I have with someone there are more ideas on how to make our platform better and expand it’s functionality. We are constantly thinking about how we can make things easier to use so that it is truly approachable by anyone!
For those of you that made it to the end, first thank you and if you want access to our model scanning - just let us know [email protected]. In the event that you work at Hugging Face or know someone who does, we want to discuss integrating our scanning on Hugging Face itself!
Appendix
Example Report
This report has had three backticks reduced to two for viewing purposes here.
# Security Scan Report
**Repository:** ScanMe/resnet-backdoored
**Scan Date:** 2025-06-18
**Total Issues Found:** 5
## Executive Summary
Critical security vulnerabilities detected requiring immediate attention. 1 critical issue found that could pose significant security risks.
⚠️ **Warning:** Pickle files with executable code detected. These files can contain malicious Python code that executes when the model is loaded.
### Issue Breakdown
| Severity | Count |
| -------- | ----- |
| Critical | 1 |
| High | 0 |
| Medium | 0 |
| Low/Info | 4 |
## Remediation Recommendations
### Critical Issues - Immediate Action Required
Address all critical security vulnerabilities before deploying this model to production. These issues pose significant security risks and could lead to system compromise.
### Pickle File Security
Pickle files containing executable code pose a significant security risk as they can execute arbitrary Python code when loaded.
**Recommended solution:** Convert pickle files to a non-executable format such as ONNX, SafeTensors, or HDF5 to eliminate code execution risks while preserving model functionality.
**Affected files:**
- `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/pytorch_model.bin`
### General Security Best Practices
- Review all detected issues in the detailed findings below
- Implement input validation and sanitization
- Consider additional security testing and code review
- Establish regular security scanning as part of your deployment pipeline
## Detailed Findings
### Finding 1: Critical - /observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/pytorch_model.bin
**File:** `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/pytorch_model.bin`
**Severity:** Critical
**MITRE ATLAS Framework:**
- [AML.T0010.003: AI Supply Chain Compromise: Model](https://atlas.mitre.org/techniques/AML.T0010.003)
- [AML.T0010: AI Supply Chain Compromise](https://atlas.mitre.org/techniques/AML.T0010)
- [AML.T0017: Backdoor ML Model](https://atlas.mitre.org/techniques/AML.T0017)
**Detection Details:**
``
Pickle contains import `__builtin__::exec`, which is a known dangerous import. This could be used to execute arbitrary code at the time of deserialization.
``
### Finding 2: Info - /observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/pytorch_model.bin
**File:** `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/pytorch_model.bin`
**Severity:** Info
**MITRE ATLAS Framework:**
- [AML.T0010.003: AI Supply Chain Compromise: Model](https://atlas.mitre.org/techniques/AML.T0010.003)
- [AML.T0010: AI Supply Chain Compromise](https://atlas.mitre.org/techniques/AML.T0010)
- [AML.T0017: Backdoor ML Model](https://atlas.mitre.org/techniques/AML.T0017)
**Detection Details:**
``json
{
"remaining_bytes": 0,
"total_pickle_ops": 11851,
"imports": {
"torch._utils": [
"_rebuild_tensor_v2"
],
"collections": [
"OrderedDict"
],
"torch": [
"FloatStorage",
"LongStorage"
],
"__builtin__": [
"exec"
]
},
"extension_registry": {}
}
``
### Finding 3: Info - /observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/.gitattributes
**File:** `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/.gitattributes`
**Severity:** Info
**Detection Details:**
``
File was not scanned due to not being identified by any scanners
``
### Finding 4: Info - /observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/README.md
**File:** `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/README.md`
**Severity:** Info
**Detection Details:**
``
File was not scanned due to not being identified by any scanners
``
### Finding 5: Info - /observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/config.json
**File:** `/observatory/.cache/huggingface/hub/models--ScanMe--resnet-backdoored/snapshots/faf9a71b8d2cb2e5398c3cde0b19d6b87eba1431/config.json`
**Severity:** Info
**Detection Details:**
``json
JSON data clipped for brevity on blog
``
---
*Report generated on 6/18/2025, 12:24:03 PM*