From Cybersecurity to AI Interpretability

The Origin Story
When you start a company, everyone asks what problem you’re solving. Here’s our story beyond the elevator pitch!
Tim founded the AI Red team at a major telecom company after years of red-teaming emerging technologies at FFRDCs and startups. While LLMs were new to him, attacking unknown systems wasn’t. A blog post on “Abliteration” (removing safety guardrails) caught Tim’s attention, especially since it didn’t require massive compute. Like most AI research, implementing it wasn’t straightforward - leading him down the “mechanistic interpretability” rabbit hole.
Think of mechanistic interpretability as a fancy term for “reverse engineering neural networks” - the perfect journey for someone experienced in reverse engineering systems!
This is when Tim approached Carl, one of the best reverse engineers he knew, about potentially starting a company around this challenge!
Carl has been mucking around the internals of obscure and misunderstood systems for the better part of a decade. His work has primarily focused on reverse engineering embedded systems with obscure architectures and specialized operating systems looking for vulnerabilities to disclose and building mitigations to prevent exploitation. To Carl, mechanistic interpretability is cybersecurity by a different name, and as such we can follow the same foundational steps to understand and protect AI systems.
Understanding a system’s capabilities is crucial for finding realistic attack vectors and robust defensive positions. The beauty of techniques like jailbreaks and prompt injections is their accessibility - they’ve democratized the offensive beginnings of AI security research and allowed anyone curious enough to participate. Colorfully characterized by some security researchers as “begging”, their brilliance lies in leveraging linguistic patterns that anyone can discover and implement. As we look to the beginnings of defensive research, we see an eerily similar approach to that from the early days of network security - (LLM) firewalls currently deploy a barrier around the unknown and filter only on malicious input and outputs.
What comes next? Can we detect model poisoning? Weight extraction? Model distillation? The constraint of only having input-output pairs was frustrating when trying to understand why certain attacks succeeded or failed as well as only providing a single instance of malicious input. Not much different than shaking the Magic 8 ball and waiting for an answer.
The Gap We Found
There are so many interesting problems around the space of AI - one can build or fine-tune models, design new foundational building blocks of neural networks, improve training efficiency, design quantization methods, map ideas internal to the model’s network, monitor the model’s performance, or attempt to secure around a model. That is to say, there are many gaps, but the problems that we found to be most interesting are those focus on the internals of a model. To effectively introduce security into a model, we must understand the internals of a model.
To understand the internals of a model we must have reliable tooling that gets out of the way. Everyone relies upon these unobtrusive tools everyday to write blogs, bill customers, send emails, have meetings, the list goes on. In our case the tools mirrors those often found in cybersecurity, disassemblers, debuggers, fuzzers, and any other tool that helps demystify the internals of binaries will be critical in the investigation of model internals. So we grabbed our model disassembler and got to work, oh wait…
The biggest current gap? Tooling. Everything was in Jupyter notebooks! As the field expands rapidly, many researchers have adopted Jupyter notebooks as the accepted form of publication for code. These notebooks often age poorly, resulting in code being referenced that no longer works. This can lead to frustration reproducing research instead of furthering that research with the same effort. While community platforms like Neuronpedia have emerged, they target AI researchers with serious math backgrounds (dust off that linear algebra, folks!). Expert tools like this fill an important role, but are the exact opposite of unobtrusive. These tools aren’t focused on usability, information overload, buzzwords, or the barrier to entry. Instead, we believe that expert users with easy to use tools allow for these experts to apply their skills to the problem, not on the tooling.
Democratizing AI Interpretability
Remember 3D printing over a decade ago? Early adopters spent more time calibrating bed levels, unclogging nozzles, and debugging firmware than actually creating. You practically needed an engineering degree just to print a simple toy.
Then came Prusa, and later Bambu Labs - suddenly you could focus on what to print rather than how to print. The community exploded with creativity once the technical barriers were reduced for owning a printer. The printer could become an unobtrusive tool, used to create anything.
We see mechanistic interpretability at that early stage right now. It’s powerful, but inaccessible - reserved for those who can navigate complex mathematics and trudge their way through research notebooks that may or may not still work. The conversation often revolves around the tools themselves rather than what insights they might unlock and we are aiming to change that.
What did large language model jailbreaks teach us? When more people access something, we discover oddities and edge cases the original model developers never imagined. This AI wave exploded because it’s so broadly applicable and adoption of AI will continue to increase through many facets of our lives.
Our goal is simple, but challenging: interpretability for everyone.
We will build tools to make interpretability accessible, no PhD required. Whether you are completely new to interpretability or an expert blazing the trail for others, tools need to enable you, not get in the way.
Our Work
We wanted to share a sneak peak of the work we have completed so far on our path to interpretability for all.
Astraloom
Our interpretability frontend, designed to be approachable with interesting news, learning paths, and tools to dive into the internals of models.
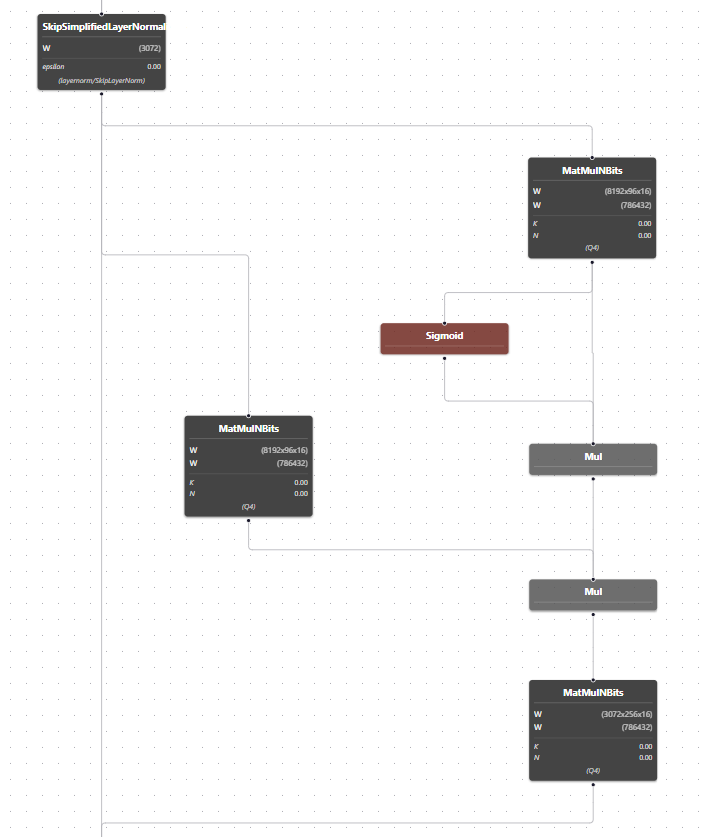
Astraloom - Graph View
Inspired by the excellent Netron, but grounded in our requirements for performance, custom integrations, and ease of use. This provides a familiar interface for any reverse engineer, but is simple to pick up and explore.
Can you identify what model this is from?
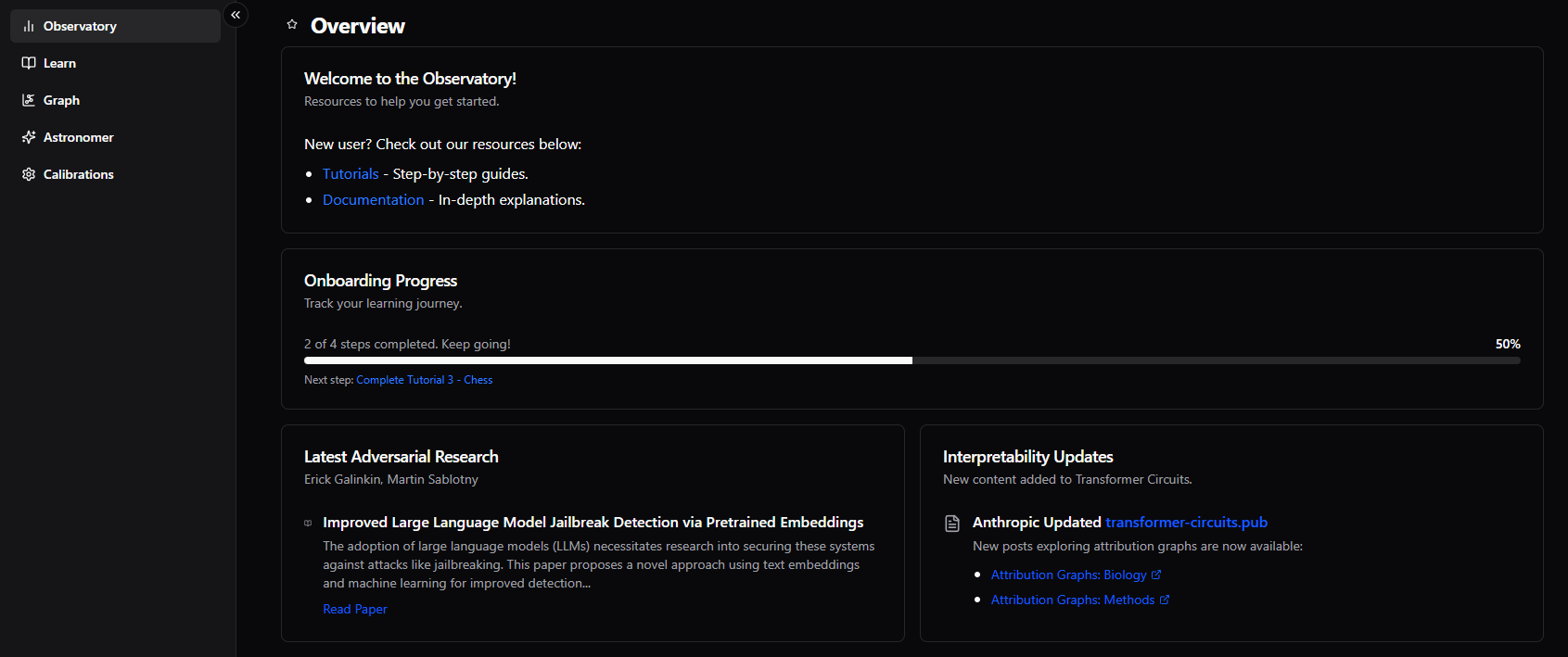
Observatory
Our custom backend, focused on performance, safety, and repeatability. While a backend may be harder to visualize it powers everything. Observatory enables us to execute custom code at any point during inference. This capability allows us to collect activations, modify values, insert additional functionality, and anything in-between. Observatory represents a real AI debugger capable of being helpful in any architecture, with any model.
Why This Matters
Is this just a fun adventure or something more? Both!
Recent research shows the broad potential of interpretability: by analyzing how AI chess models work, Google DeepMind discovered lessons that could help human Grandmasters narrow the human-AI knowledge gap, while Anthropic showed giving AI security teams access to interpretability tools help detect tampered models.
Wouldn’t it be cool to access these capabilities without working at those labs? We would love to have that level of understanding accessible to everyone and their applications, so we are building it.
We see applications for interpretability everywhere - defense, high speed trading, and cybersecurity all represent immediate use cases for improved understanding and insights into neural networks and AI. If you agree or want to know more - Contact us!
Want to get the latest updates from us? Subscribe to our newsletter!