AI's Security Amnesia: Rediscovering Known Solutions

AI Interpretability Needs More Cybersecurity
I had partially penned a blog around the importance of interpretability, however Dario Amodei - the CEO of Anthropic was kind enough to write a lengthy blog on the topic yesterday here which I would highly encourage everyone to read!
It can be easily characterized as a call to action, with a passionate plea for more people to join the race to reverse engineer AI models before they get too intelligent to be interpreted! Due to the importance of this problem, Anthropic announced that they are ramping up spending on this challenge and invited other AI labs to do the same. Upon reading through it, I had a nagging feeling the whole time - this sounds familiar…
Anyone in cybersecurity may have had the same one - “wait a minute this sounds just like the argument for security, and I know how this story goes”. While there are some novelties to every field, much of what was outlined isn’t unique to AI. Talking to other cybersecurity folks, there seems to be a consistent trend of AI research teams “rediscovering the wheel” on problems that are well defined in other fields.
I’ll make my case here for why for AI Interpretability can likely move forward faster if the focus is on exploring lateral thinking and enabling experts from other areas.
Starting straight with a quote from the referenced blog:
Recently, we did an experiment where we had a “red team” deliberately introduce an alignment issue into a model (say, a tendency for the model to exploit a loophole in a task) and gave various “blue teams” the task of figuring out what was wrong with it. Multiple blue teams succeeded; of particular relevance here, some of them productively applied interpretability tools during the investigation.
The “breakthrough” described above is the well defined and scoped cybersecurity concept of performing adversary emulation and detection engineering through a purple team exercise. Better logs and better tooling equals better results! I’ve been a big advocate for purple teaming for a while, and I think it is great that we’re seeing the potential value in AI safety & security!
I feel it is important to point out a pretty crucial detail that I feel oversells the generality of the outlined purple team exercise - it requires access to training data, and access to specialized tooling that organizations haven’t been able to even buy. How do I know you can’t even buy access to these? Because I wanted to, and couldn’t find anything.
Some readers at this point may say - “well but AI is different, there is the threat to humanity that doesn’t exist anywhere else!” I would love to point you towards the optimistic sounding book section by established journalists that have been covering cybersecurity for a while (seriously, I highly recommend reading these):
- Countdown to Zero Day: Stuxnet and the Launch of the World’s First Digital Weapon by Kim Zetter
- Sandworm: A New Era of Cyberwar and the Hunt for the Kremlin’s Most Dangerous Hackers by Andy Greenberg
- This is How They Tell Me the World Ends: The Cyberweapons Arms Race by Nicole Perlroth
Side note - depending how deep down the rabbit hole you want to go, also check out the Darknet Diaries podcast.
Let’s dive into another area with significant overlaps that seem to be ignored - building defenses for AI models. For defending against jailbreaks, and attempting to collect the unicorns of universal jailbreaks - bug bounties are all the rage, trying to collect adversarial inputs to build better defenses. I want to be super clear that I think building better defenses is good. However, coming from a test and evaluations background I have strong opinions on how tests are setup and the true effectiveness of solutions being claimed as a result. The cybersecurity parallel here isn’t hard - it’s not like cybersecurity companies have been trying to game or over market solutions for a while:
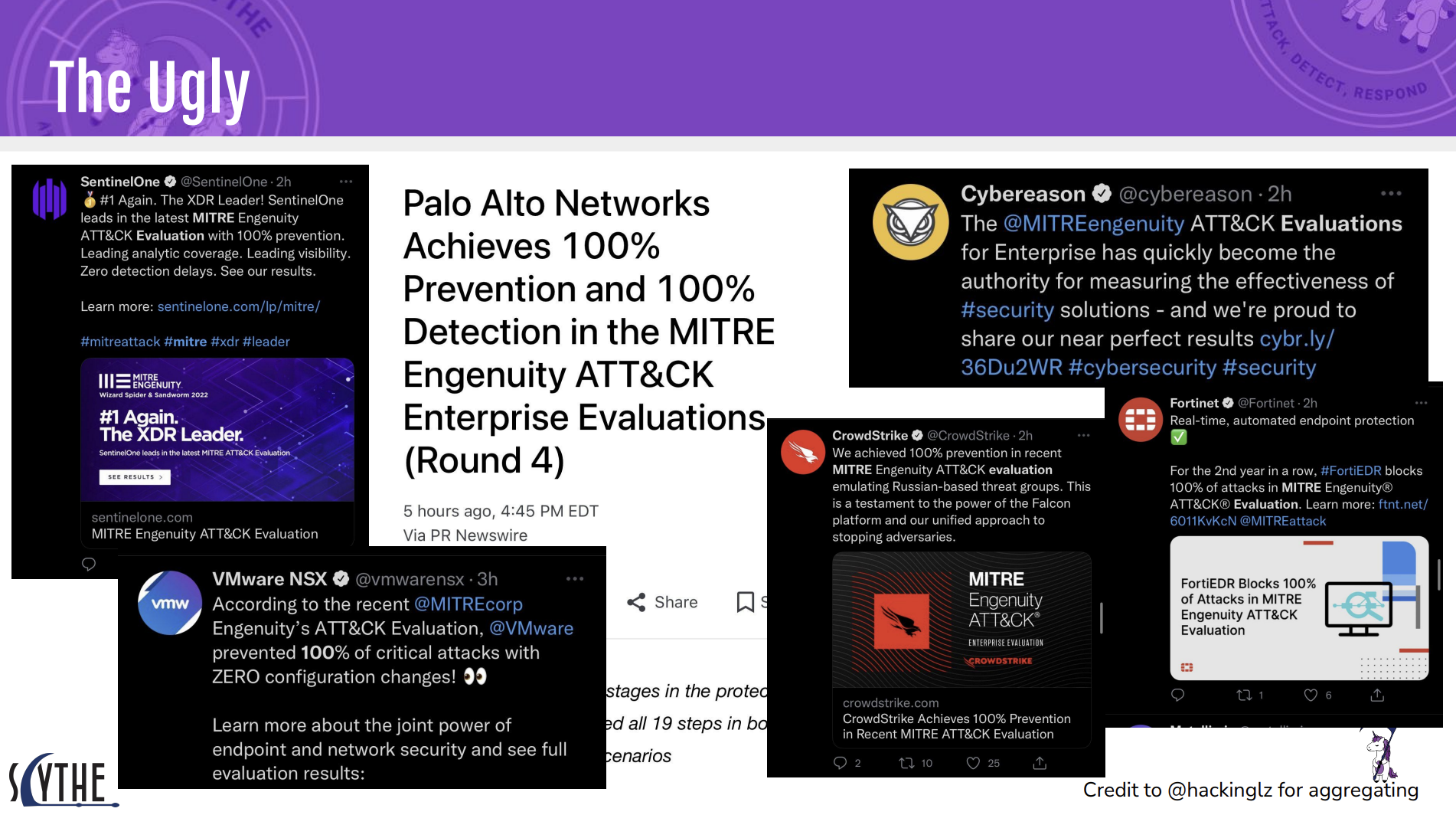 An ATT&CK Evals Slide I made from 2022
An ATT&CK Evals Slide I made from 2022
A lot of the new defenses in AI outside of published ones like Spotlighting (Credit to Microsoft) rely on security through obscurity - “we published a new model that detects bad, come test it through this API or gamified interface”. Security through obscurity does have some value and is worth it’s place in a defender’s toolbox, but the challenge here is that folks evaluating these models are not being given even close to a fair fight because the tooling available doesn’t even begin to give testers anything beyond some initial variants of fuzzing. Let’s draw our comparisons here to cybersecurity again in exploring the vulnerability discovery process.
For binaries, vulnerability researchers tend to get to do a level of reverse engineering with tools like debuggers, perform static and dynamic analysis (Ghidra, Binary Ninja, Ida Pro), AND leverage input automation tools like fuzzers to deconstruct the mechanisms around how these things work. Finding a vulnerability is a long complicated step by itself. Weaponizing the vulnerability can be another whole skillset!
Ask even some of the best reverse engineers to find a zero day without being able to hook up a test environment, getting a copy of a binary, or even having access to tools like a debugger and they’d rightly laugh at you. That is the equivalent of how these jailbreak defense tests are being set up.
As a tail end to the discussion, there is a video by one of the same AI safety teams that references a “Swiss Cheese” approach to layering defenses for AI safety, which isn’t a bad way to characterize defense in depth to broad audiences! That is, until one of the other team members references that it may not be a well known approach. Defense in Depth is probably the most well known paradigm in cybersecurity.
Aiming to give these teams the benefit of the doubt - they come across as naive at best. Against the backdrop of the predicted challenges of interpreting and controlling super intelligent AI, why aren’t these teams learning or leveraging the decades of research done in relevant domains? Why should they be trusted as the “representatives of humanity” against this potential existential threat?
Cybersecurity teams have been defending networks against malicious threat actors for decades, oftentimes having to defend organizations with little to no budget to match adversary capabilities or expertise.
While offering criticism, I also will propose solutions -
First, new AI teams need to expand where and likely how they are hiring. Restricting your hiring to SF and NYC like a majority of AI companies have done is a massive inhibitor for security talent. As a specific example, while there are exceptions most of the best reverse engineering teams are not on the west coast (or in NYC). There is a professional industry around people reverse engineering black boxes and has been since long before LLMs.
Second, AI teams that really believe in prioritizing safety and security need experienced cybersecurity (and other domain!) experts at the table with a substantial voice in discussions. There are unique challenges around securing AI models that will require specialized expertise, however not all of the challenges are as unique as they are currently being characterized. Figuring out what is unique and what can use tried and tested solutions will accelerate progress since there can be focus. Collaboration is key here.
Third (the sales pitch!) is that tooling to enable non-experts has to be better and easier to use. Part of the reason we started Starseer is I literally could not buy a solution I was looking for, so we knew there was a market need. An aggregation of interpretability methods and techniques tied to easy to use UI’s and work flows not requiring advanced degrees, heavy math backgrounds, or wading through expert jargon is essential with the proliferation of AI across all industries. Every cybersecurity expert we have given a demo to so far has immediately understood the value of what our platform offers because it is a workflow they are familiar with. Democratizing access to these kinds of capabilities also tends to move research forward because there is a floor in expertise that platforms provide, so researchers can focus on the bleeding edge instead of having to worry about underlying reliability and repeatability of things like Jupyter Notebooks. I’ll end the pitch with - if this resonates and sounds like a capability you would like then please contact us!
Interpretability of AI is an extremely important issue, and I want to make sure and acknowledge that there are genuinely novel challenges with the space which is what makes it so fascinating! Identifying and focusing on those issues as soon as possible will enable us to find paths forward. We believe that collaborating with and enabling others outside of current interpretability experts is going to be the best path forward for the tackling the potential downsides.
Thanks for reading!
Tim