
Your AI is only as valuable as your team's trust in it.
Catch reasoning drift before it hits your P&L. The one failure mode your existing monitoring cannot see.
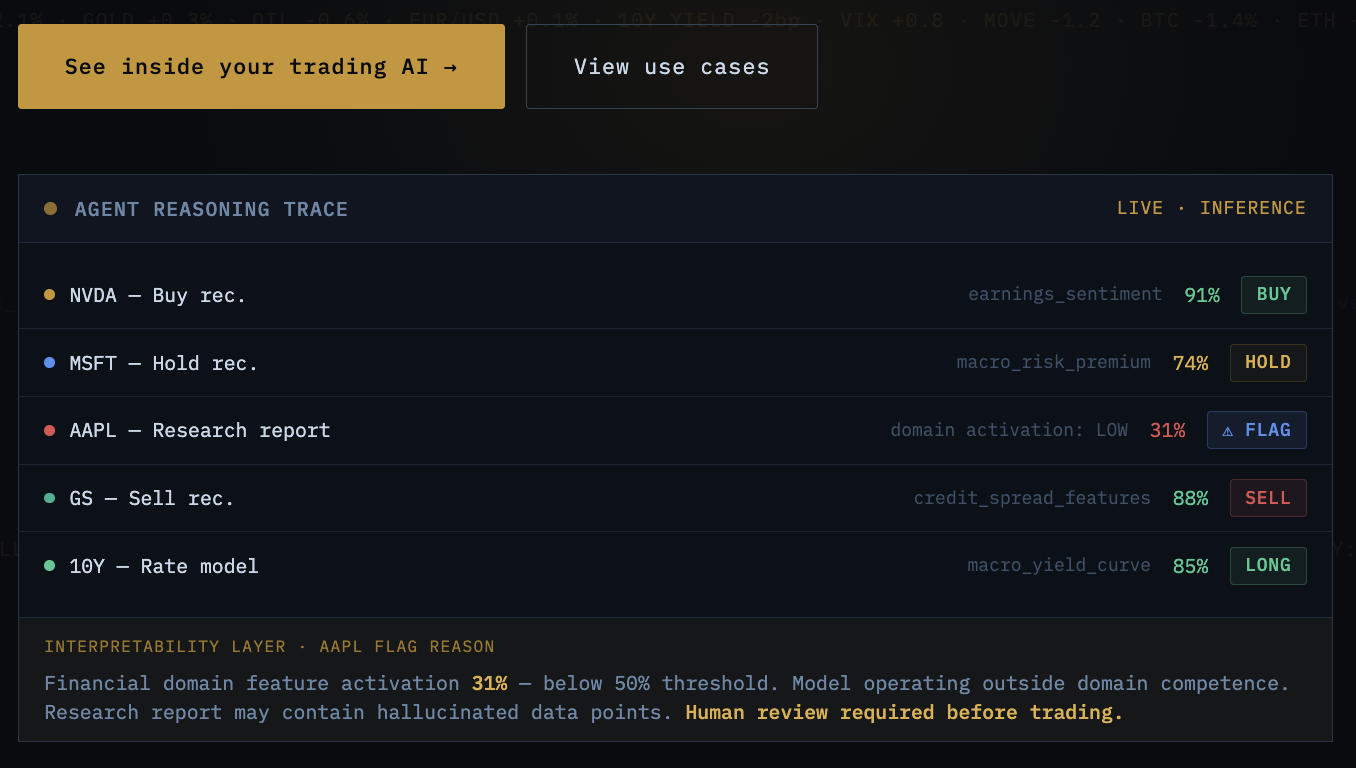
AI-Quant reveals why your models recommend a trade, not just that they did. Mechanistic interpretability applied to quantitative AI: multi-agent reasoning transparency, hallucination detection at the feature level, alpha signal drift monitoring, and model-internal audit trails that satisfy regulators and PMs alike.
— The Trust Deficit
When a PM asks "why does
the model say buy?"
Every quant AI team faces the same fundamental tension: the more autonomous the AI becomes, the less the humans trust it. And in trading, trust isn't philosophical — it's measured in dollars. A portfolio manager will not risk real capital on a recommendation they can't understand.
The best you can currently offer is a generated rationale — text that sounds plausible but may not reflect what the model actually computed internally. That's not transparency. That's a press release written by the same black box.
Black-box trade recommendations
PMs override good AI recommendations because they can't verify the reasoning, leaving alpha on the table every time a valid signal is dismissed without evidence.
Reasoning drift before output drift
Trading models silently drift in production — internal reasoning changes while outputs temporarily look stable. You find out when it hits P&L, not before.
Hallucinated data in research
LLMs generating financial analysis can fabricate statistics that flow directly into P&L simulations. In a trading workflow, hallucinated data destroys capital.
Multi-agent disagreement opacity
When the sentiment agent and fundamental agent disagree on a trade, there is no way to determine which one reasoned correctly versus got lucky.
Audit trails are generated text
Regulators are moving toward mandatory explainability. Your current audit trail is generated text, not computational evidence — and that distinction is going to matter.
— Alpha Signal Drift
Reasoning changes before outputs do.
That's the problem.
Output monitoring only sees results, not the model's internal reasoning — creating a blind spot where drift can occur while outputs still look normal.
AI-Quant closes this gap by monitoring activations and circuits during inference, detecting reasoning drift at the source before it impacts decisions.

— How AI-Quant Works
Mechanistic interpretability.
Not approximation.
Circuit tracing during inference
Instruments deployed models to trace activation circuits in real time, revealing which internal features fire and how they combine to produce the output.
Feature activation monitoring
Continuously measures domain-relevant financial feature activations during inference. Flags domain competence degradation before a bad output reaches a trade decision.
Multi-agent reasoning attribution
Traces what each agent activated on, where agents diverged, and which reasoning chain was grounded in domain features versus coincidental confidence.
Reasoning drift detection
Establishes internal reasoning baselines per model and monitors deviation — catching the failure mode that destroys quant capital before it reaches P&L.
Computational audit trail
Generates verifiable activation traces, feature weights, and circuit paths — evidence-based audit trails that satisfy regulatory scrutiny rather than generated explanations.

— Starseer AI-Quant Platform
Built on the same interpretability engine
as Model Validation.
Mechanistic Interpretability Engine
Instead of approximating model behavior from the outside, AI-Quant dissects activations and circuits within the model to produce verifiable evidence rather than plausible approximations — the same mechanism that finds backdoors now monitors reasoning quality.
Feature Activation & Hallucination Detection
Continuously monitors domain-relevant feature activations during inference. Detects not just that a model hallucinated, but why — by identifying which features were absent or misfiring when it did.
Multi-Agent Reasoning & Drift Detection
Traces what each specialized agent activated on, where agents diverged, and which reasoning chain was grounded in domain features. Establishes baselines and monitors deviation over time — catching the failure mode that matters most.
Feature Steering & Computational Audit Trail
Runtime intervention suppresses identified biases and corrects reasoning patterns at inference time — without retraining. Every decision generates machine-readable activation records satisfying IOSCO, EU AI Act, and SEC explainability requirements.
— Industry Use Cases
Where AI-Quant applies.
.png?width=2000&height=250&name=starseer_quant_tabs%20(1).png)
— Differentiation
Why traditional tools
need AI-Quant.
Actual internal computation, not approximation
Traces how the model processes inputs via circuits, activations, weights, and attention — not post-hoc statistical approximations of what might have mattered.
Explains why, not just what
Pinpoints missing or weak features, enabling targeted fixes instead of blind retries. The difference between knowing a recommendation failed and knowing why it will fail again.
Model-internal layer beneath observability
Adds reasoning insight your existing observability stack cannot reach. AI-Quant complements, not replaces, what you already have — it operates at the layer beneath all of it.
Computational evidence for regulators
Activation records, weights, and circuit traces that meet IOSCO, EU AI Act, and SEC explainability requirements — not generated text a regulator can challenge, but verifiable computational evidence.
— Frequently Asked Questions
Common questions about AI-Quant.
How is AI-Quant different from the explainability tools we already use (SHAP, LIME, or output evaluation platforms)?
SHAP and LIME are post-hoc approximations that try to explain a model's decision after it's made, from the outside, using statistical inference about which inputs mattered. They cannot tell you what the model actually computed internally. Output evaluation platforms detect that a model hallucinated. AI-Quant reveals why it hallucinated — by examining which domain-relevant features were active or absent during inference. These tools are complementary. AI-Quant operates beneath them, at the model-internal layer none of them can reach.
We already log every AI input and output for our regulators. Isn't that sufficient for explainability requirements?
Logging what was asked and answered gives you the record. It doesn't give you the reasoning. IOSCO's March 2025 report and the EU AI Act's explainability requirements are moving toward requiring firms to demonstrate how their AI systems made decisions — not just that they were used. A log of inputs and outputs tells a regulator what the model saw and said. AI-Quant's computational audit trail tells them what the model actually reasoned. That distinction is the difference between a defensible regulatory response and a generated explanation a regulator can challenge.
Our quant team is already building internal interpretability capability. Why would we need AI-Quant?
Internal research proves concepts but doesn't productize at scale. Managing sparse autoencoder training, maintaining financial feature dictionaries, and running runtime activation monitoring across dozens of production models requires platform-level infrastructure that most internal teams can't build alongside their core research responsibilities. AI-Quant accelerates what your team is already doing — providing production-grade tooling so your interpretability researchers can focus on financial domain problems rather than the infrastructure beneath them.
Does AI-Quant require access to our model weights, training data, or proprietary trading logic?
AI-Quant monitors model behavior during inference. It requires access to activation outputs from your deployed models — not to weights, training data, or trading logic. For organizations with strict IP and data security requirements, AI-Quant supports air-gapped and on-premises deployment options. Nothing about your proprietary models, strategies, or data leaves your environment.
Which AI systems does AI-Quant support, and does it work with fine-tuned or RAG-augmented models?
AI-Quant applies to transformer-based language models, including fine-tuned models, RAG-augmented pipelines, and multi-agent orchestration systems built on LLM foundations. Fine-tuned and RAG-augmented models are specifically where AI-Quant provides the most value — these are the models where you don't fully control what was learned during training, where domain competence is hardest to verify, and where hallucination risk is highest. Contact us to confirm support for your specific stack.
— Get Started
Your models are recommending trades.
Do you know why?
Start your free trial and see what your trading AI is actually reasoning — before the next recommendation you can't explain.